
Bio
Industrial Outreach and Collaboration
News
Publications
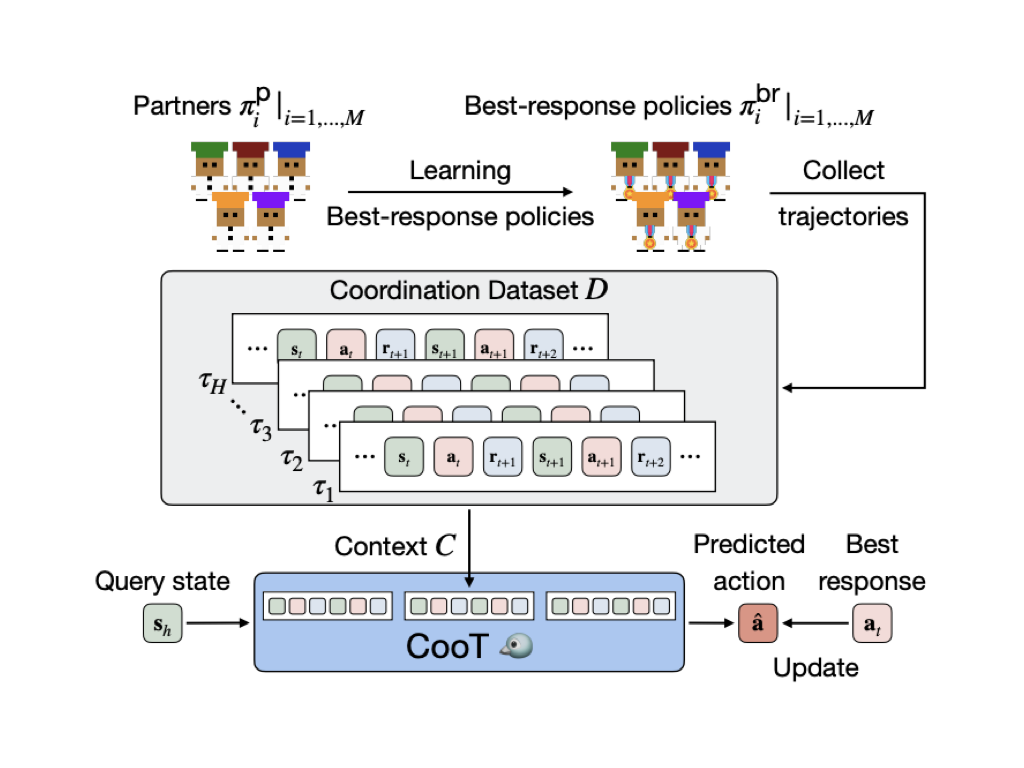
We propose Coordination Transformers (CooT), a framework that leverages in-context learning for real-time partner adaptation. Unlike prior ICL approaches that focus on task generalization, CooT is designed to generalize across diverse partner behaviors. Trained on trajectories from behavior-preferring agents, it learns to align actions with partner intentions purely through observation. We evaluate CooT on two challenging multi-agent benchmarks: Overcooked and Google Research Football. Results show that CooT consistently outperforms population-based methods, gradient-based fine-tuning, and Meta-RL baselines, achieving stable and rapid adaptation without parameter updates.
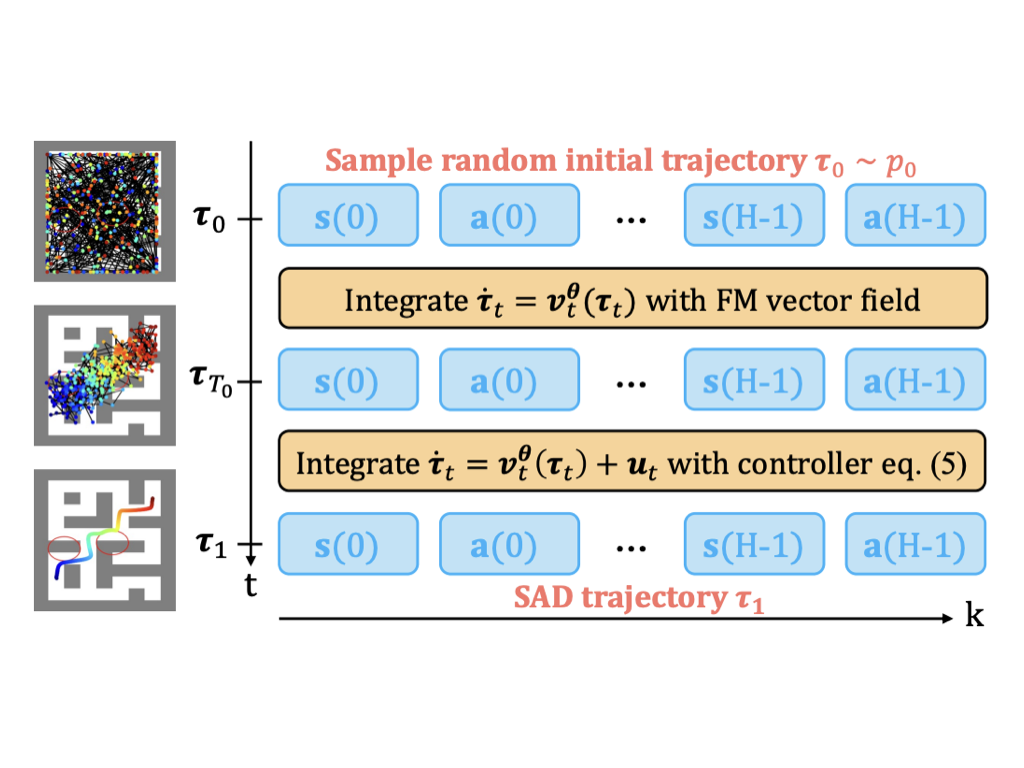
We propose SAD-Flower, a novel framework for generating \textbf{S}afe, \textbf{A}dmissible, and \textbf{D}ynamically consistent trajectories. Our approach relies on an augmentation of the flow with a virtual control input. Thereby, principled guidance can be derived using techniques from nonlinear control theory, providing formal guarantees for state constraints, action constraints, and dynamic consistency. Crucially, SAD-Flower operates without retraining, enabling test-time satisfaction of unseen constraints. Through extensive experiments across several tasks, we demonstrate that SAD-Flower outperforms various generative-model-based baselines in ensuring constraint satisfaction.
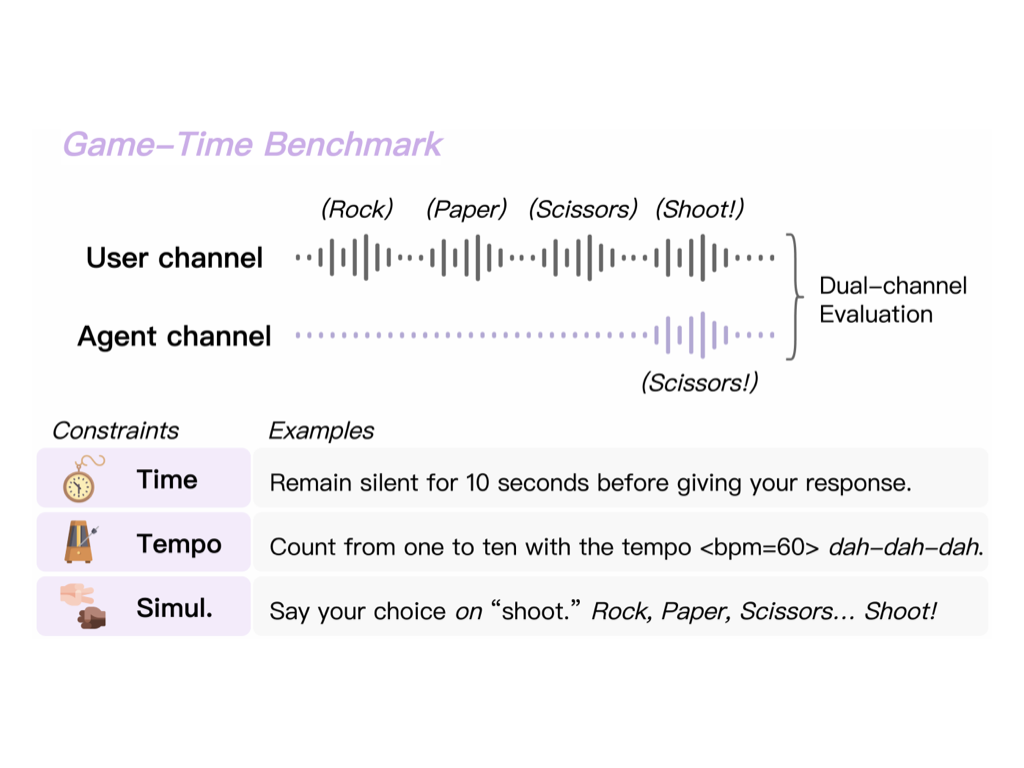
We introduce the Game-Time Benchmark, a framework to systematically assess these temporal capabilities. Inspired by how humans learn a language through language activities, Game-Time consists of basic instruction-following tasks and advanced tasks with temporal constraints, such as tempo adherence and synchronized responses. Our evaluation of diverse SLM architectures reveals a clear performance disparity: while state-of-the-art models handle basic tasks well, many contemporary systems still struggle with fundamental instruction-following. More critically, nearly all models degrade substantially under temporal constraints, exposing persistent weaknesses in time awareness and full-duplex interaction. The Game-Time Benchmark provides a foundation for guiding future research toward more temporally-aware conversational AI.

We propose Preference Vector, a novel framework inspired by task arithmetic. Instead of optimizing multiple preferences within a single objective, we train separate models on individual preferences, extract behavior shifts as preference vectors, and dynamically merge them at test time. This modular approach enables fine-grained, user-controllable preference adjustments and facilitates seamless integration of new preferences without retraining. Experiments show that our proposed Preference Vector framework improves helpfulness without excessive conservatism, allows smooth control over preference trade-offs, and supports scalable multi-preference alignment.

We systematically examine, analyze, and compare representative creativity measures--creativity index, perplexity, syntactic templates, and LLM-as-a-Judge--across diverse creative domains, including creative writing, unconventional problem-solving, and research ideation. Our analyses reveal that these metrics exhibit limited consistency, capturing different dimensions of creativity. We highlight key limitations, including the creativity index's focus on lexical diversity, perplexity's sensitivity to model confidence, and syntactic templates' inability to capture conceptual creativity. Additionally, LLM-as-a-Judge shows instability and bias. Our findings underscore the need for more robust, generalizable evaluation frameworks that better align with human judgments of creativity.
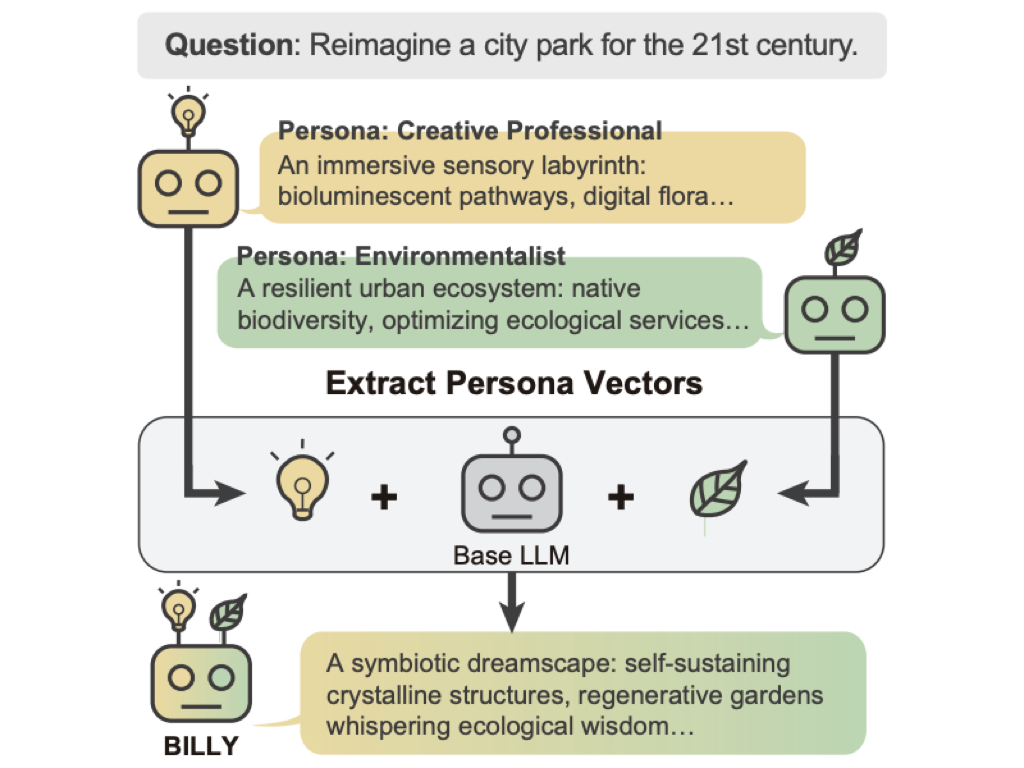
Multi-LLM systems enhance the creativity of large language models by simulating human collective intelligence but suffer from significant drawbacks, such as high computational costs and inference latency. To address these limitations, we propose BILLY (BlendIng persona vectors for Large Language model creativitY), a training-free framework that captures the benefits of multi-LLM collaboration, i.e. inducing diverse perspectives and specialized expertise, within a single model. BILLY operates by extracting and blending multiple distinct persona vectors directly in the model's activation space. We steer the model's generation process with this merged vector while inference, enabling multi-perspective output without explicit multi-LLM communication.

This paper presents a systematic analysis revealing that fine-tuning with LLM-generated data not only improves target task performance but also reduces non-target task degradation compared to fine-tuning with ground truth data. Through analyzing the data sequence in tasks of various domains, we demonstrate that this enhancement of non-target task robustness stems from the reduction of high perplexity tokens found in LLM-generated sequences. To the best of our knowledge, this is the first work to provide an empirical explanation based on token perplexity reduction to mitigate catastrophic forgetting in LLMs after fine-tuning, offering valuable insights for developing more robust fine-tuning strategies.
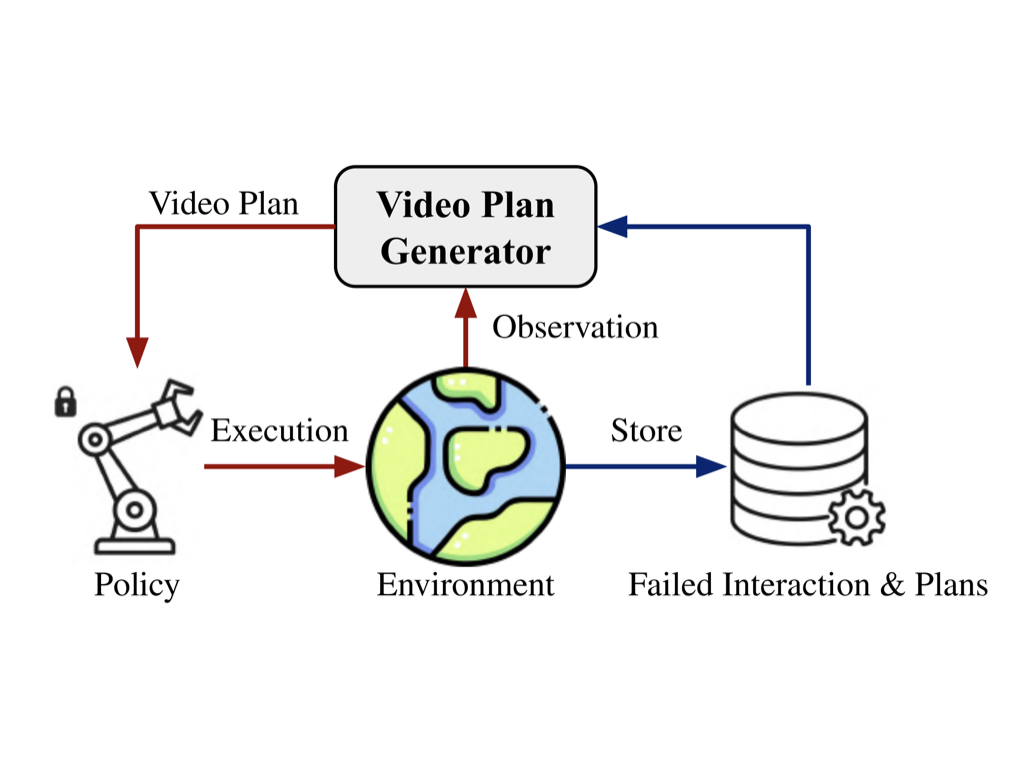
We introduce a novel framework that integrates interaction-time data into the video planning process. Our approach updates model parameters online and filters out previously failed plans during generation. This enables implicit state estimation, allowing the system to adapt dynamically without explicitly modeling unknown state variables. We evaluate our framework through extensive experiments on a new simulated manipulation benchmark, demonstrating its ability to improve replanning performance and advance the field of video-based decision-making.
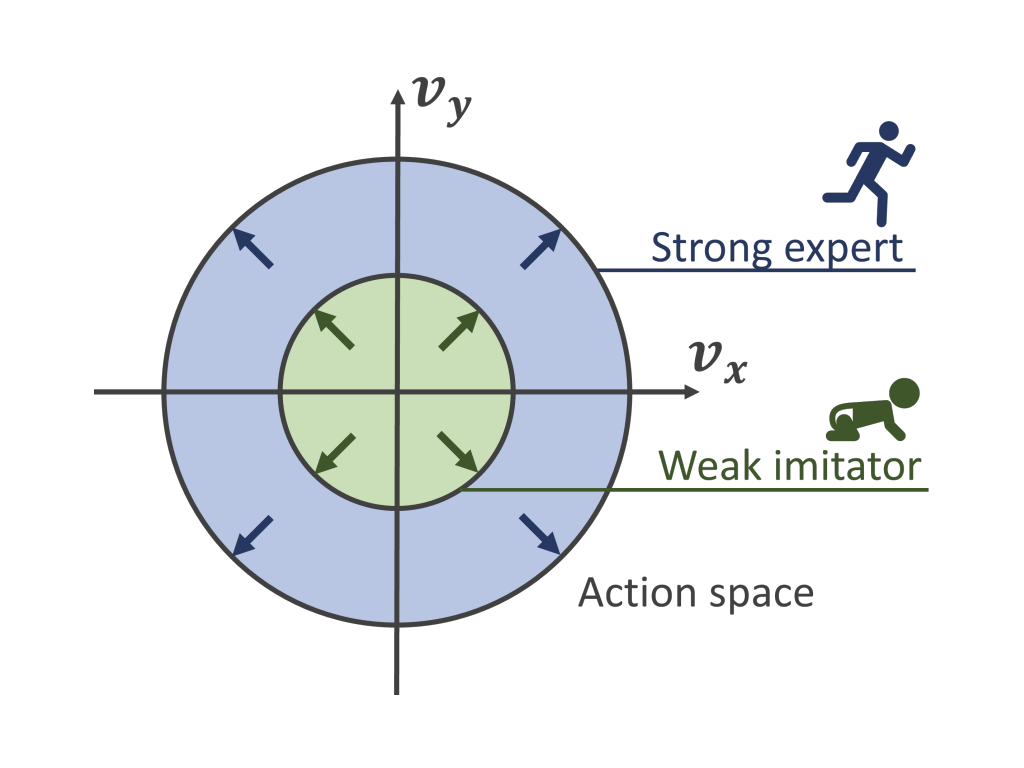
We study a new problem setting termed Action-Constrained Imitation Learning (ACIL), where an action-constrained imitator aims to learn from a demonstrative expert with larger action space. We tackle the mismatch of occupancy measure between the expert and the imitator through trajectory alignment and propose DTWIL, which replaces the original expert demonstrations with a surrogate dataset that follows similar state trajectories while adhering to the action constraints. Specifically, we recast trajectory alignment as a planning problem and solve it via model predictive control, which aligns the surrogate trajectories with the expert trajectories based on the dynamic time warping distance.
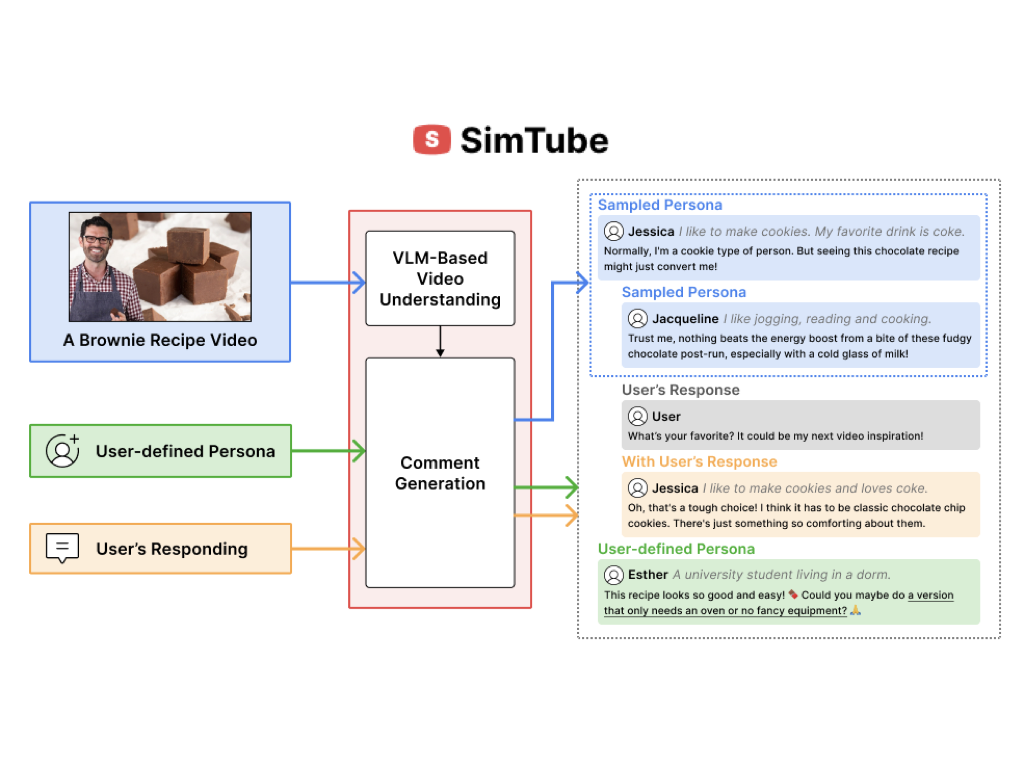
We introduce SimTube, a generative AI system designed to simulate audience feedback in the form of video comments before a video’s release. SimTube features a computational pipeline that integrates multimodal data from the video—such as visuals, audio, and metadata—with user personas derived from a broad and diverse corpus of audience demographics, generating varied and contextually relevant feedback. Furthermore, the system’s UI allows creators to explore and customize the simulated comments.
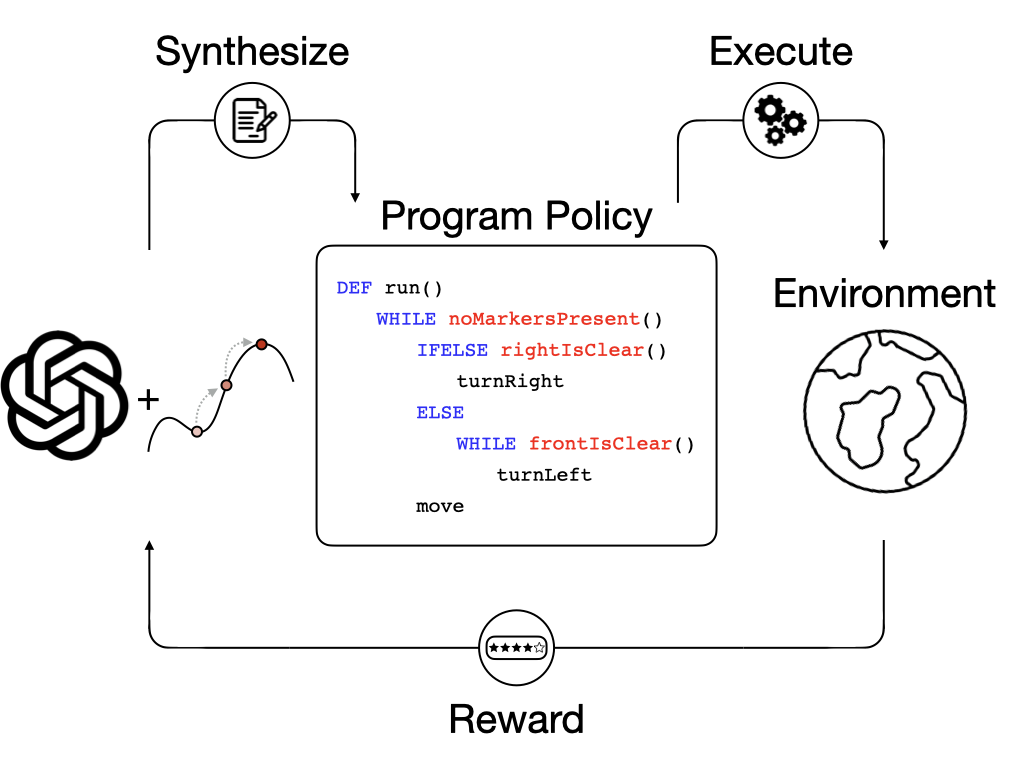
We address the challenge of LLMs' inability to generate precise and grammatically correct programs in domain-specific languages (DSLs) by proposing a Pythonic-DSL strategy — an LLM is instructed to initially generate Python codes and then convert them into DSL programs. To further optimize the LLM-generated programs, we develop a search algorithm named Scheduled Hill Climbing, designed to efficiently explore the programmatic search space to improve the programs consistently.
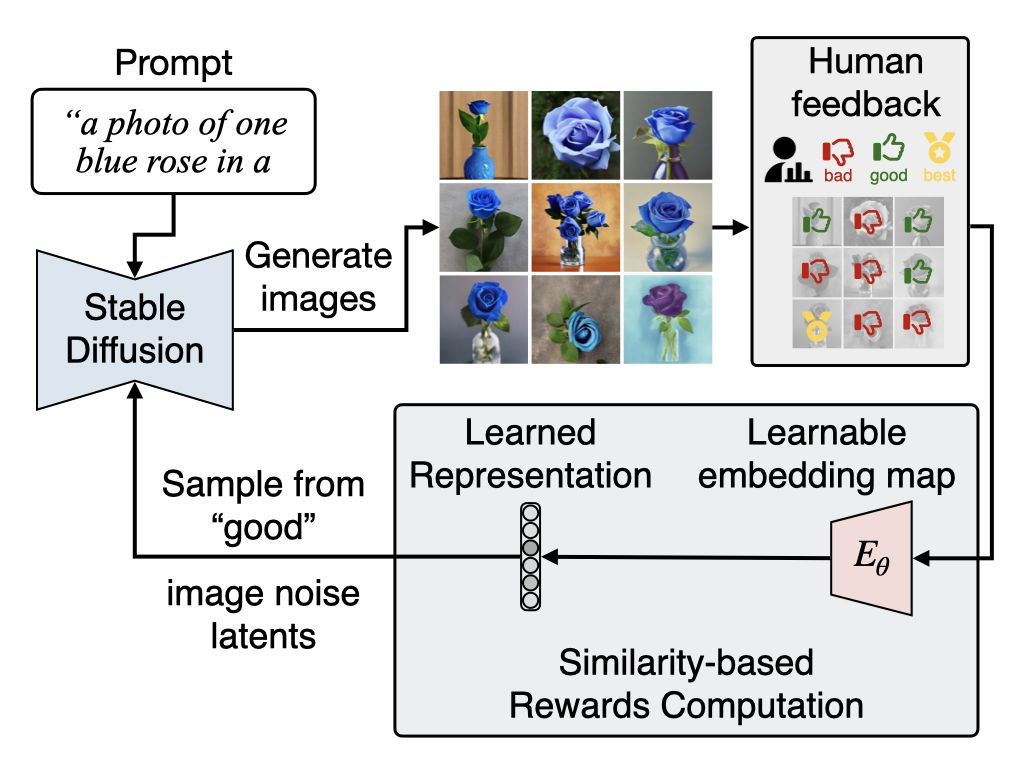
To effectively and efficiently utilize human feedback, we develop a framework, HERO, which leverages online human feedback collected on the fly during model learning. Specifically, HERO features two key mechanisms: (1) an online training method that captures human feedback and provides informative learning signals for fine-tuning, and (2) generating images from SD's refined initialization samples, enabling faster convergence towards the evaluator's intent.

We propose a generic and computationally efficient framework that can adapt a standard unconstrained RL method to action-constrained reinforcement learning. To enforce the action constraints, we leverage the classic acceptance-rejection method, where we treat the unconstrained policy as the proposal distribution and derive a modified policy with feasible actions. To improve the acceptance rate of the proposal distribution, we construct an augmented two-objective Markov decision process, which include additional self-loop state transitions and a penalty signal for the rejected actions.
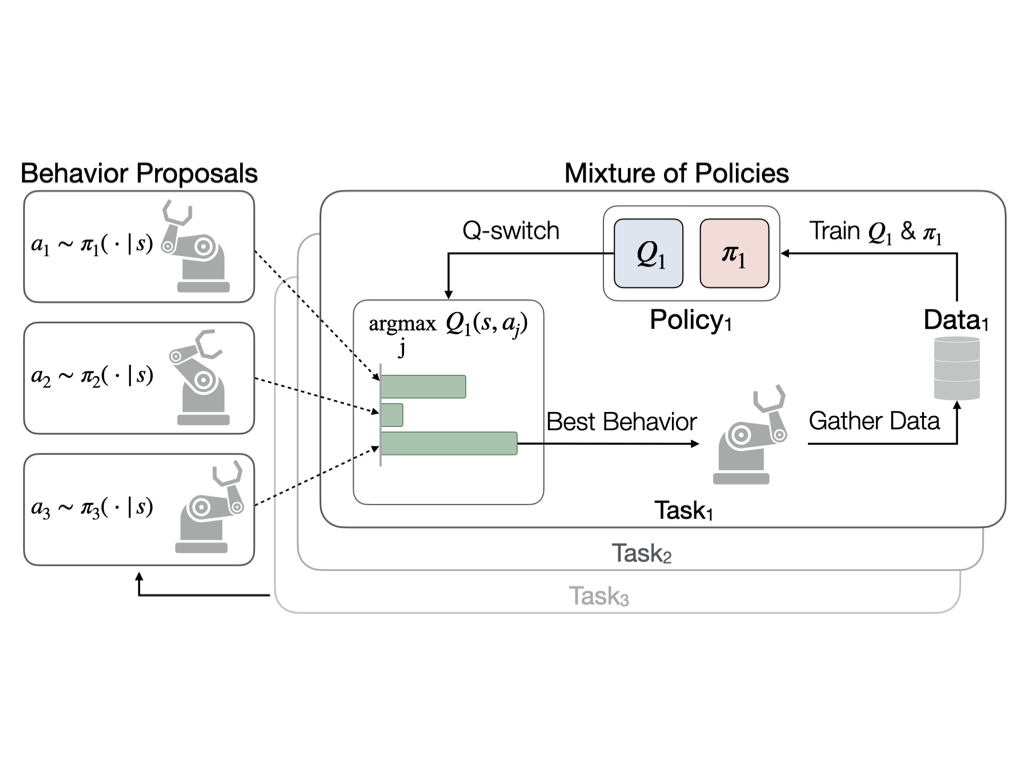
We propose a multi-task reinforcement learning method, Q-switch Mixture of policies (QMP), that can share exploratory behavior, which can be helpful even when the optimal behaviors differ. Furthermore, as we learn each task, we can guide the exploration by sharing behaviors in a task and state dependent way. QMP learns to selectively share exploratory behavior between tasks by using a mixture of policies based on estimated discounted returns to gather training data.
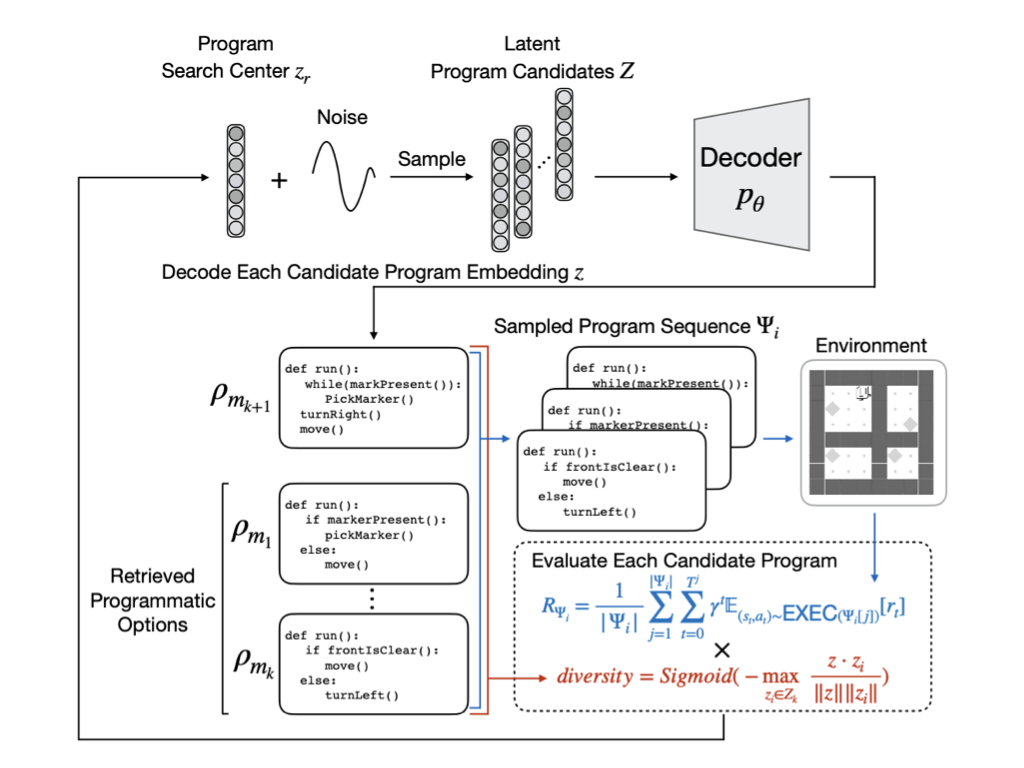
We propose the Hierarchical Programmatic Option framework (HIPO), which aims to solve long and repetitive RL problems with human-readable programs as options (low-level policies). Specifically, we proposed a method that retrieves a set of effective, diverse, and compatible programs as options (programmatic options). Then, we learn a high-level policy to effectively reuse these programmatic options to solve reoccurring subtasks.
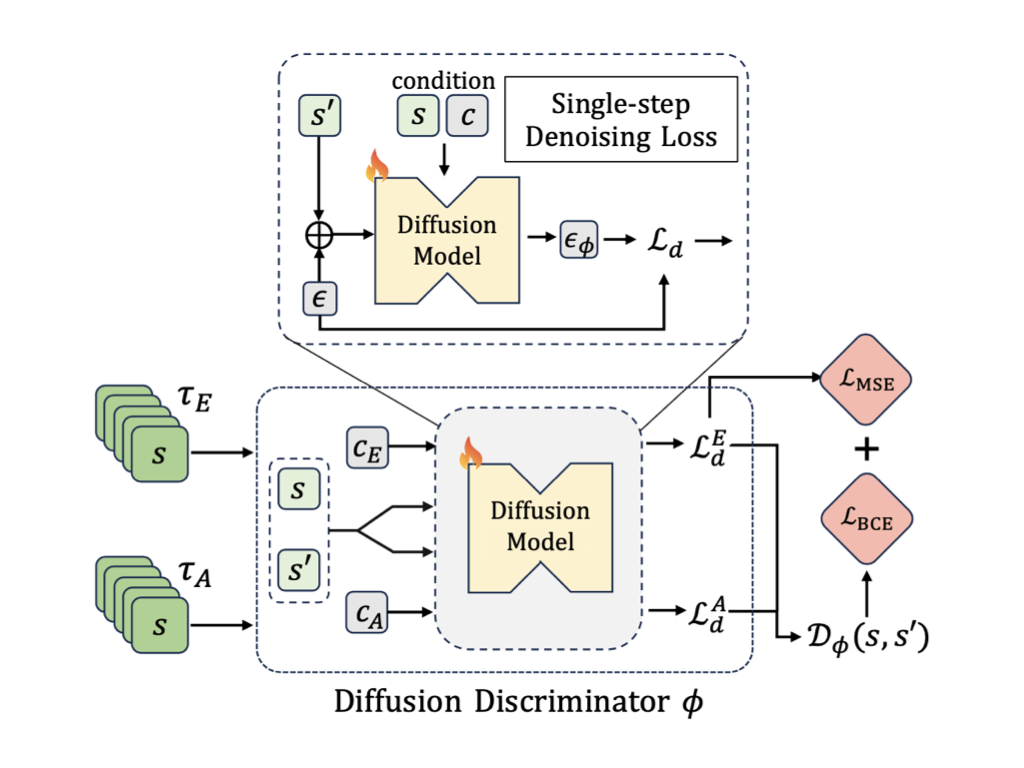
Learning from Observation (LfO) aims to imitate experts by learning from state-only demonstrations without requiring action labels. We propose to integrate a diffusion model into the adversarial imitation learning from observation framework. Specifically, we employ a diffusion model to capture expert and agent transitions by generating the next state, given the current state. Then, we reformulate the learning objective to train the diffusion model as a binary classifier and use it to provide "realness" rewards for policy learning.
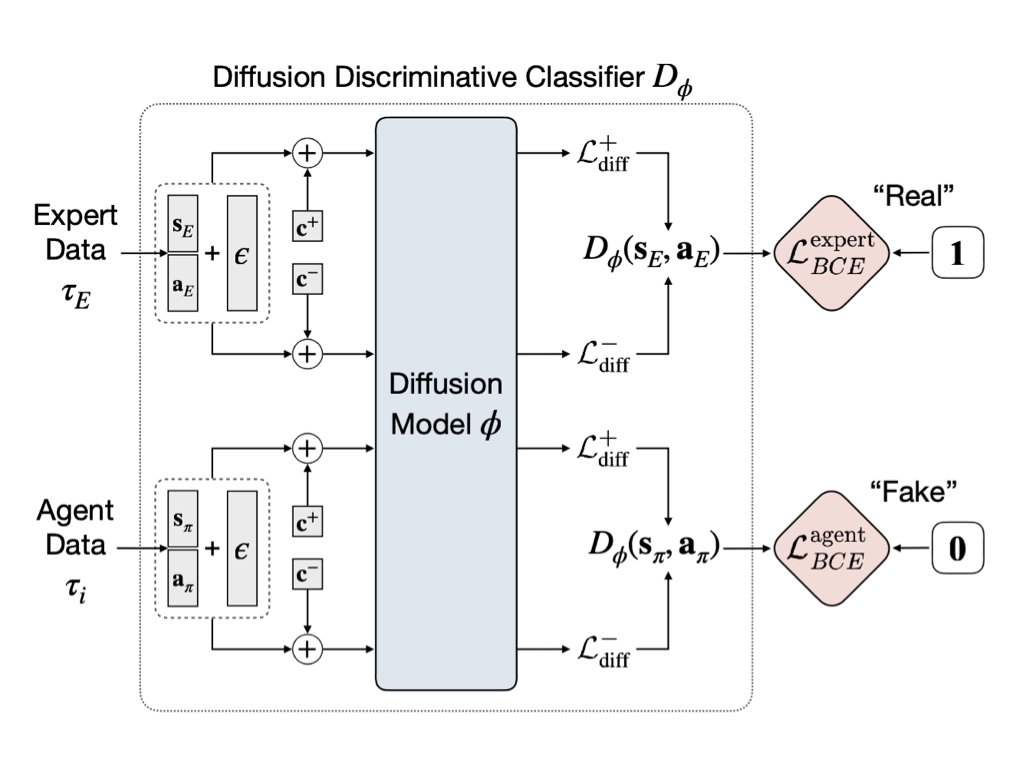
This work proposes Diffusion-Reward Adversarial Imitation Learning (DRAIL), which integrates a diffusion model into GAIL, aiming to yield more precise and smoother rewards for policy learning. Specifically, we propose a diffusion discriminative classifier to construct an enhanced discriminator; then, we design diffusion rewards based on the classifier's output for policy learning.
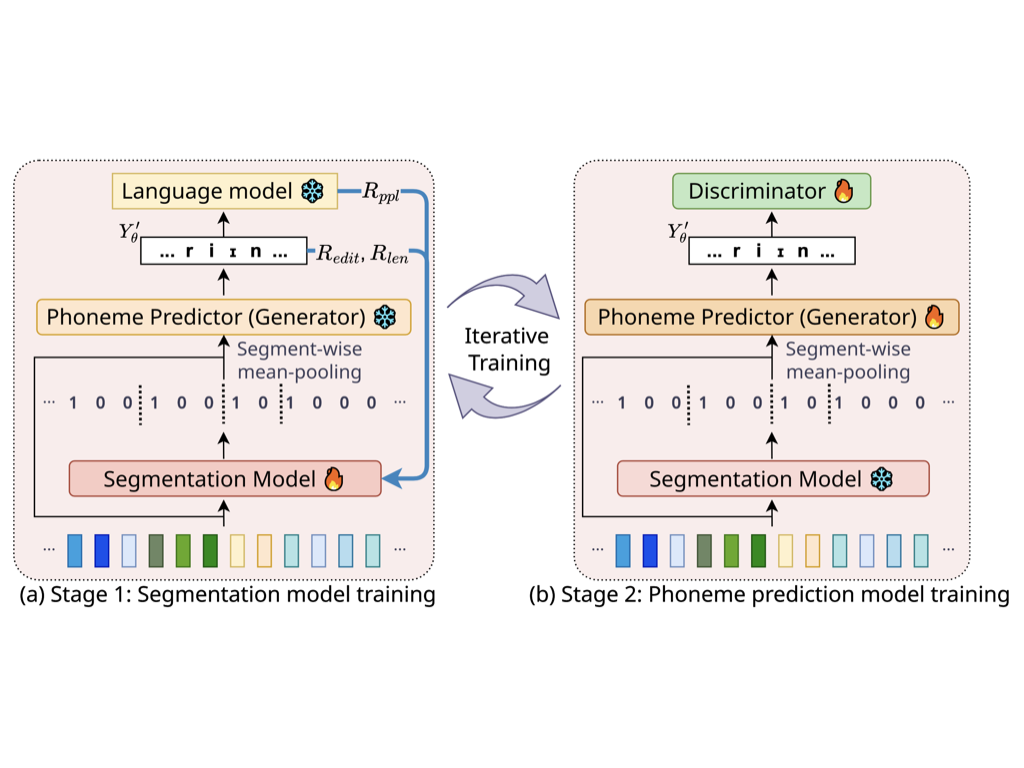
We propose REBORN, which alternates between (1) training a segmentation model that predicts the boundaries of the segmental structures in speech signals and (2) training the phoneme prediction model, whose input is a segmental structure segmented by the segmentation model, to predict a phoneme transcription. Since supervised data for training the segmentation model is not available, we use reinforcement learning to train the segmentation model to favor segmentations that yield phoneme sequence predictions with a lower perplexity.
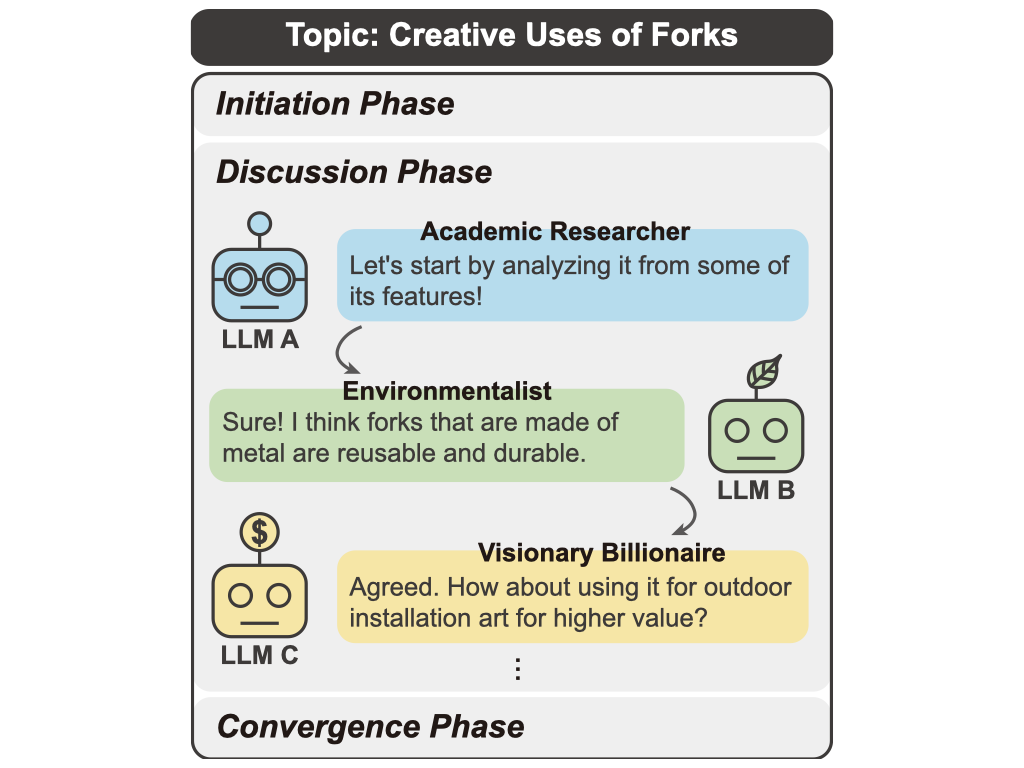
Large language models (LLMs) have shown exceptional proficiency in natural language processing but often fall short of generating creative and original responses to open-ended questions. To enhance LLM creativity, our key insight is to emulate the human process of inducing collective creativity through engaging discussions with participants from diverse backgrounds and perspectives. To this end, we propose LLM Discussion, a three-phase discussion framework that facilitates vigorous and diverging idea exchanges and ensures convergence to creative answers. Moreover, we adopt a role-playing technique by assigning distinct roles to LLMs to combat the homogeneity of LLMs.
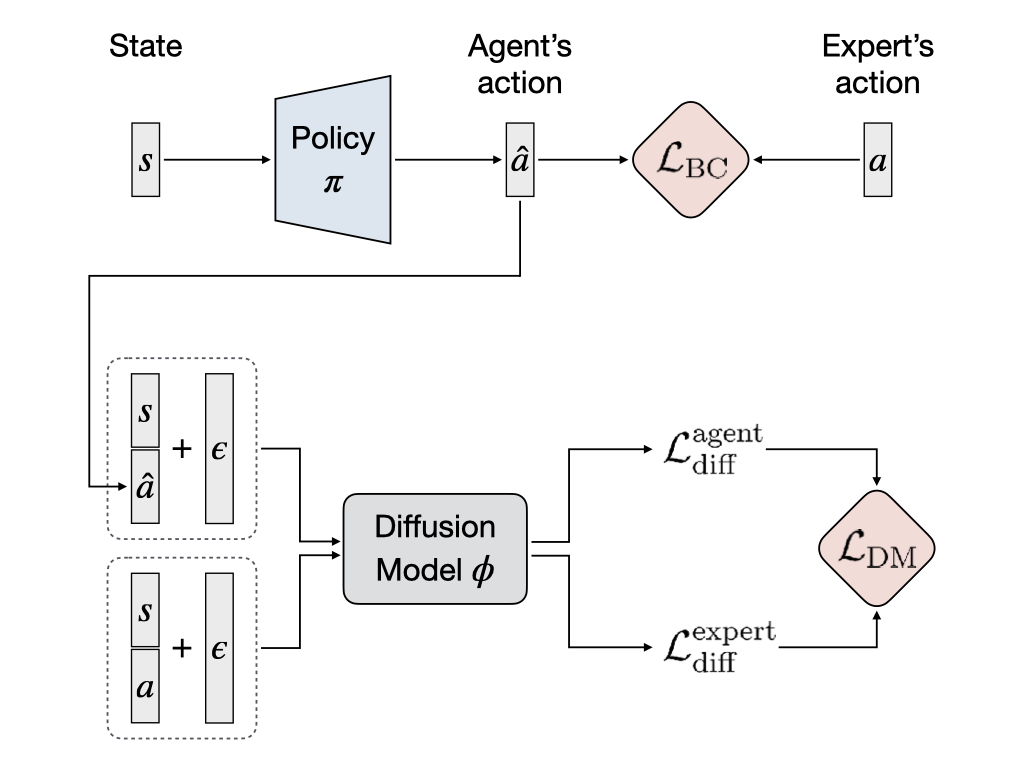
This work aims to augment BC by employing diffusion models for modeling expert behaviors, and designing a learning objective that leverages learned diffusion models to guide policy learning. To this end, we propose diffusion model-augmented behavioral cloning (Diffusion-BC) that combines our proposed diffusion model guided learning objective with the BC objective, which complements each other. Our proposed method outperforms baselines or achieves competitive performance in various continuous control domains, including navigation, robot arm manipulation, and locomotion.
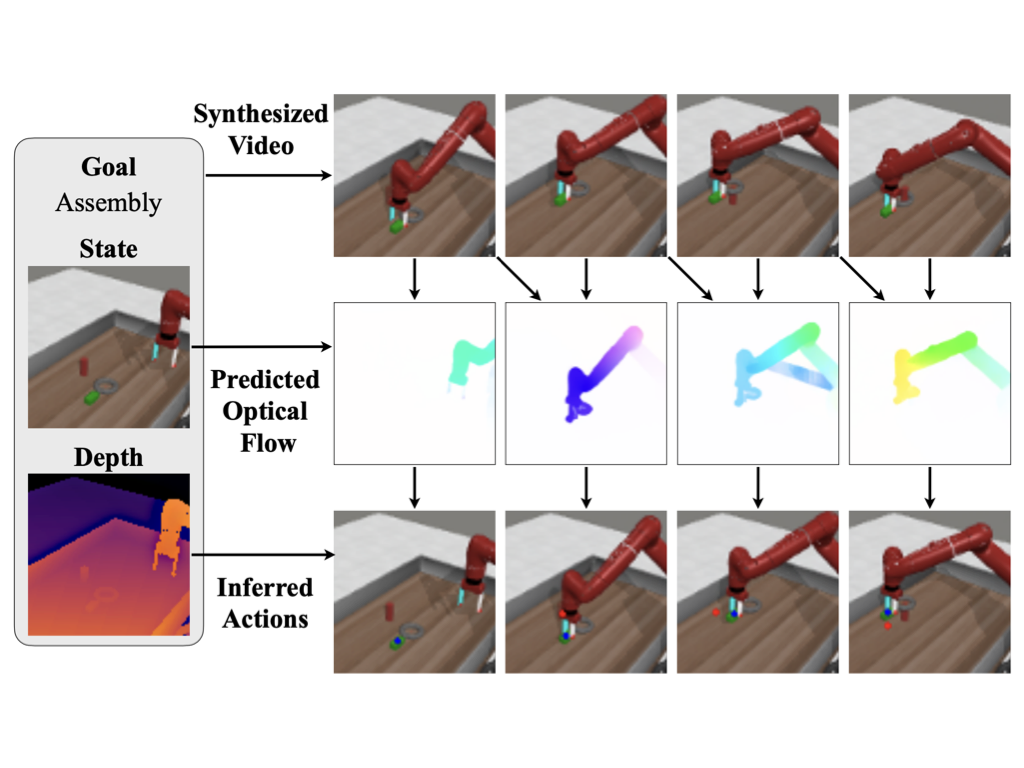
Our method leverages images as a task-agnostic representation, encoding both the state and action information, and text as a general representation for specifying robot goals. By synthesizing videos that “hallucinate” robots executing actions and in combination with dense correspondences between frames, our approach can infer the closed-formed action to execute in an environment without requiring any explicit action labels, allowing us to learn from RGB videos and acquire various robotic tasks.
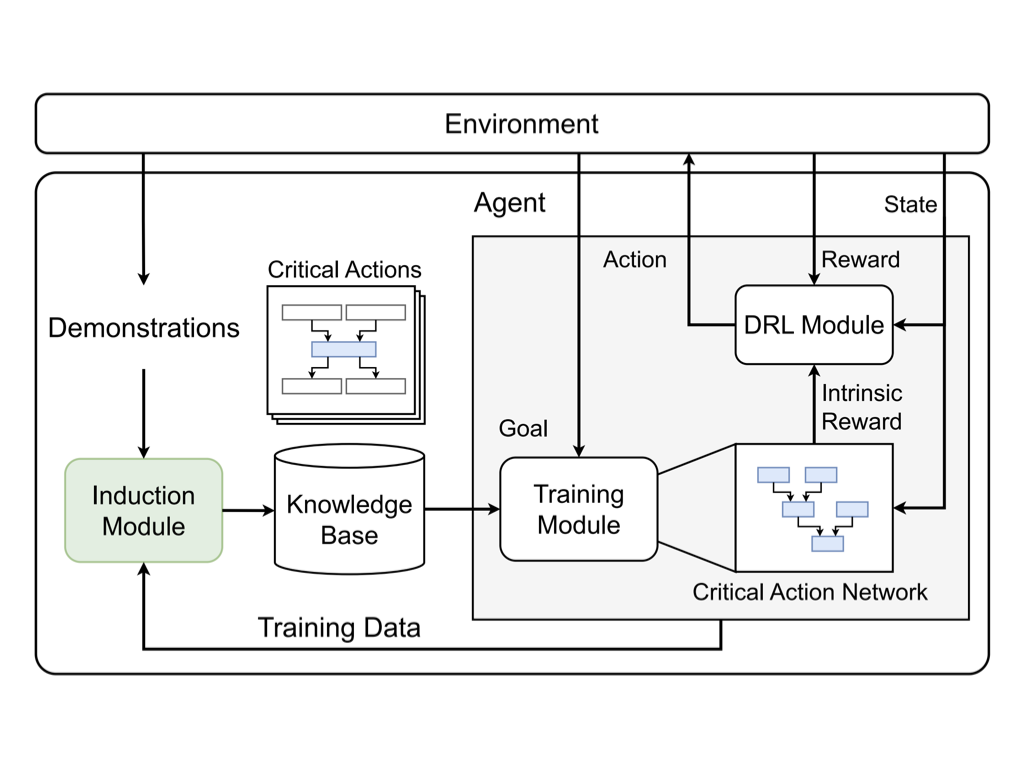
We propose a framework that integrates deep reinforcement learning with classical planning by automatically inducing task structures and substructures from a few demonstrations. Specifically, we adopt abstraction mapping formulation and define critical actions that lead to the transition at the abstraction level. Then, we propose to induce critical action schemata regarded as subtasks by employing genetic programming where the program model reflects prior domain knowledge of effect rules.

Our approach BOSS (BOotStrapping your own Skills) learns to accomplish new tasks by performing "skill bootstrapping," where an agent with a set of primitive skills interacts with the environment to practice new skills without receiving reward feedback for tasks outside of the initial skill set. This bootstrapping phase is guided by large language models that inform the agent of meaningful skills to chain together. Through this process, BOSS builds a wide range of complex and useful behaviors from a basic set of primitive skills.
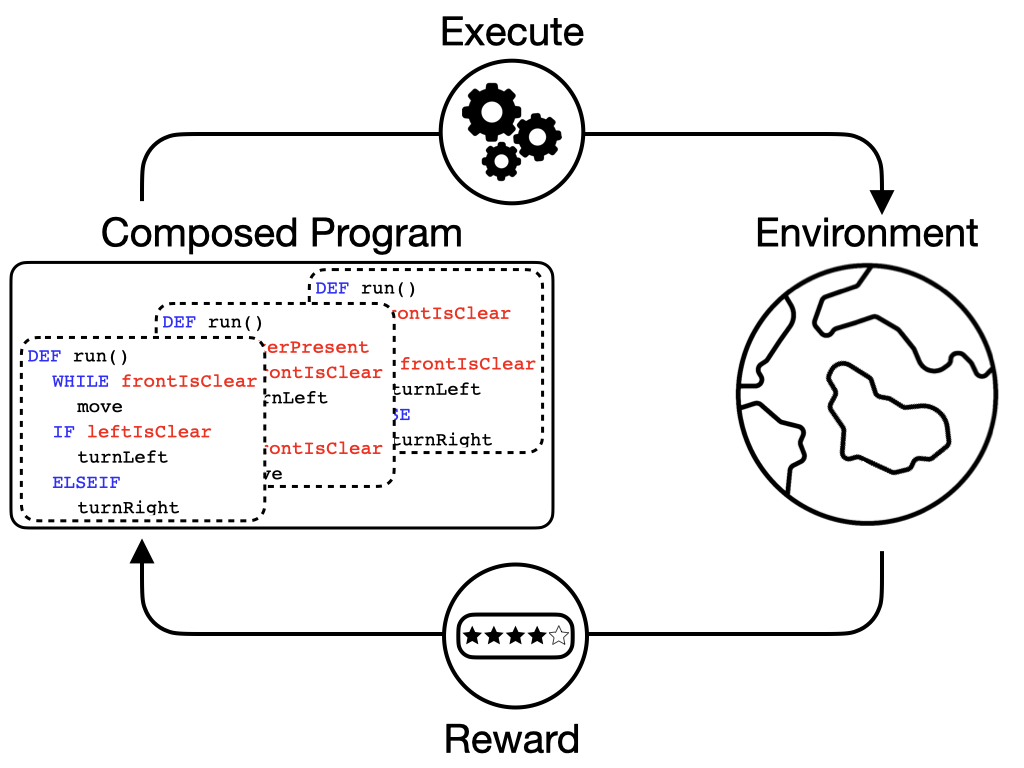
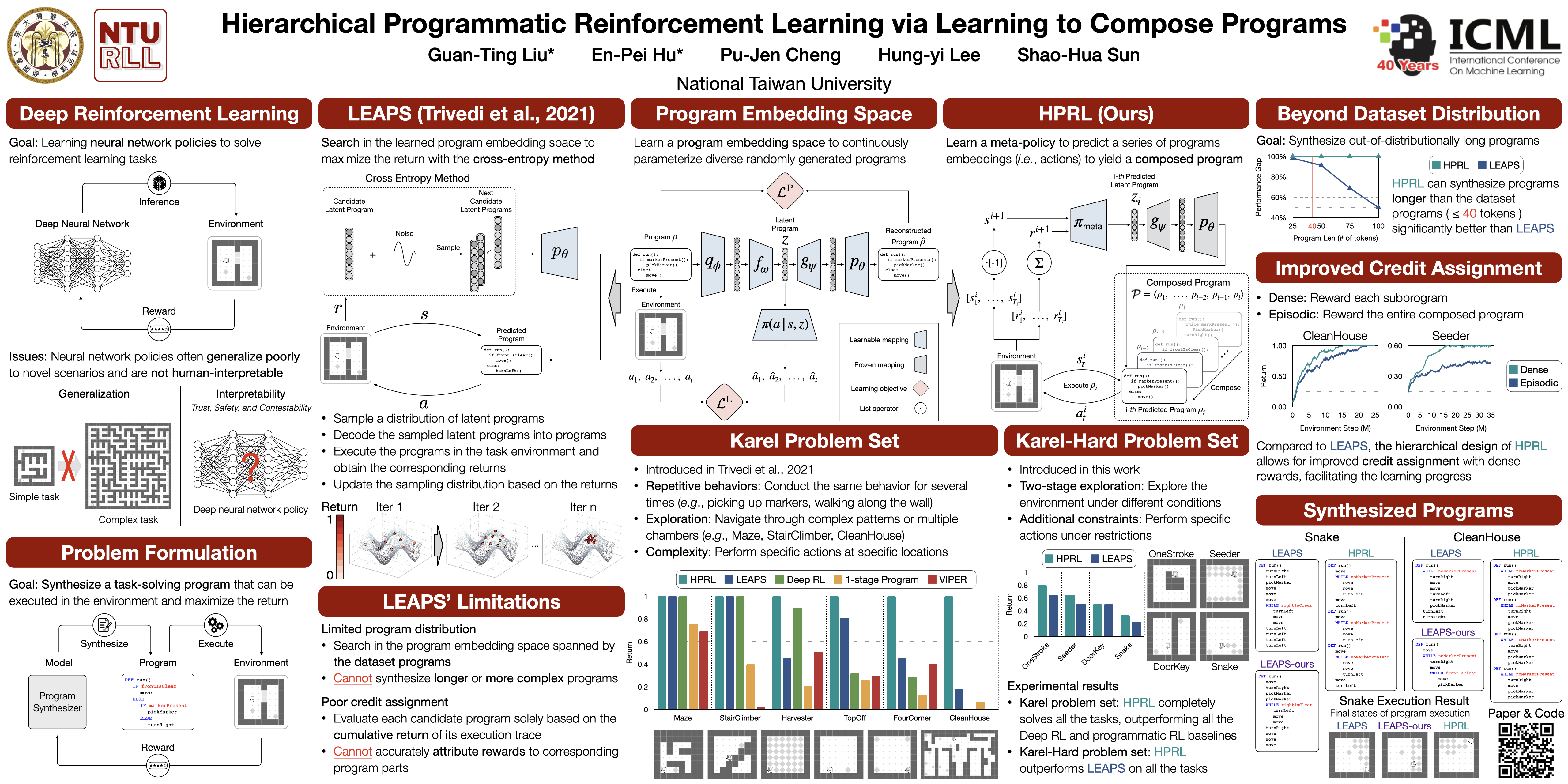
We re-formulate solving a reinforcement learning task as synthesizing a task-solving program that can be executed to interact with the environment and maximize the return. We first learn a program embedding space that continuously parameterizes a diverse set of programs sampled from a program dataset. Then, we train a meta-policy, whose action space is the learned program embedding space, to produce a series of programs (i.e., predict a series of actions) to yield a composed task-solving program.
{kind=link}
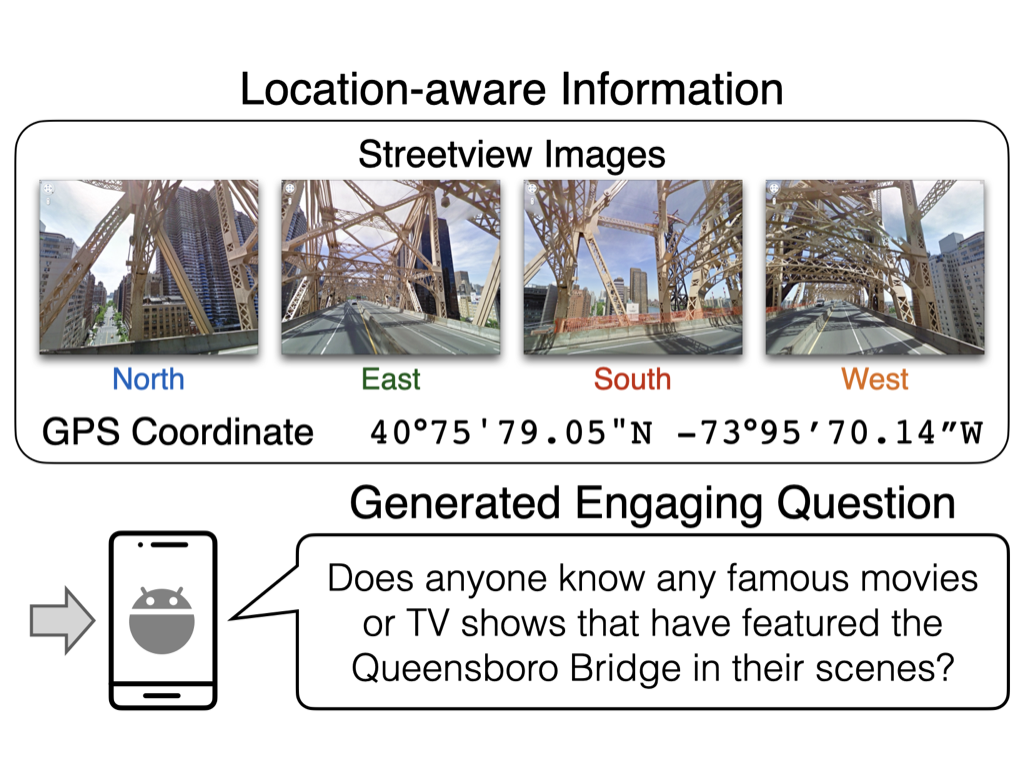
This work introduces a novel task, location-aware visual question generation (LocaVQG), which aims to generate engaging questions from data relevant to a particular geographical location (e.g.,surrounding images and its GPS coordinate). To tackle this task, we present a dataset generation pipeline that leverages GPT-4 to produce diverse and sophisticated questions. We propose methods to train lightweight models which can reliably generate engaging questions from location-aware information.
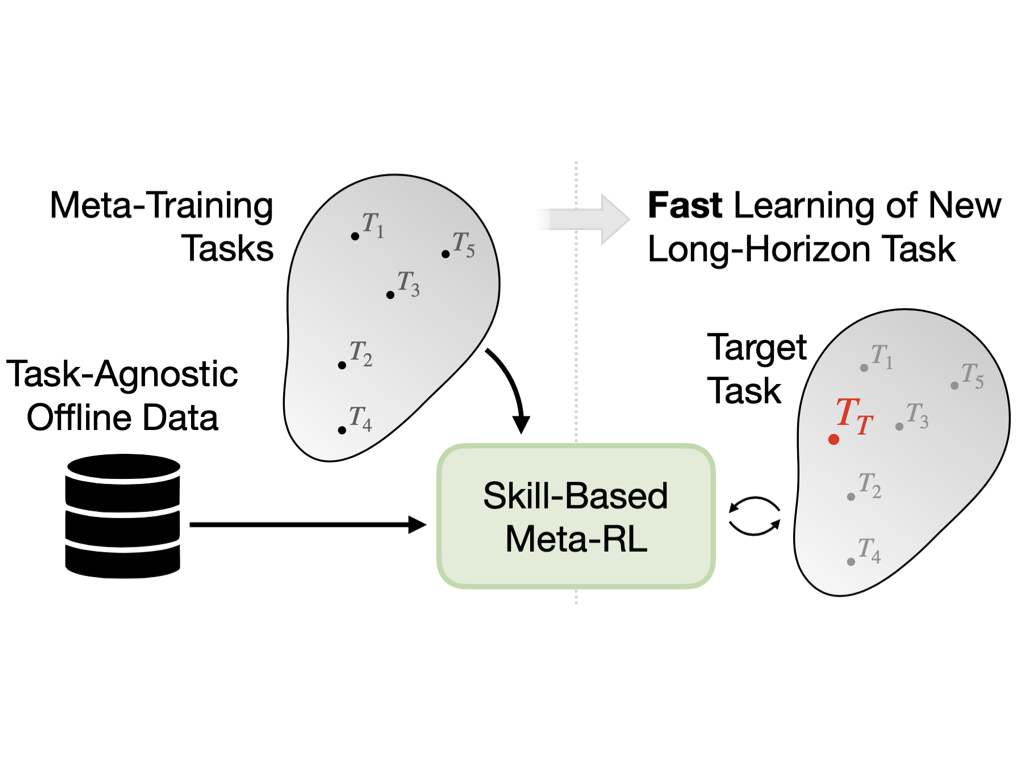
We devise a method that enables meta-learning on long-horizon, sparse-reward tasks, allowing us to solve unseen target tasks with orders of magnitude fewer environment interactions. Specifically, we propose to (1) extract reusable skills and a skill prior from offline datasets, (2) meta-train a high-level policy that learns to efficiently compose learned skills into long-horizon behaviors, and (3) rapidly adapt the meta-trained policy to solve an unseen target task.
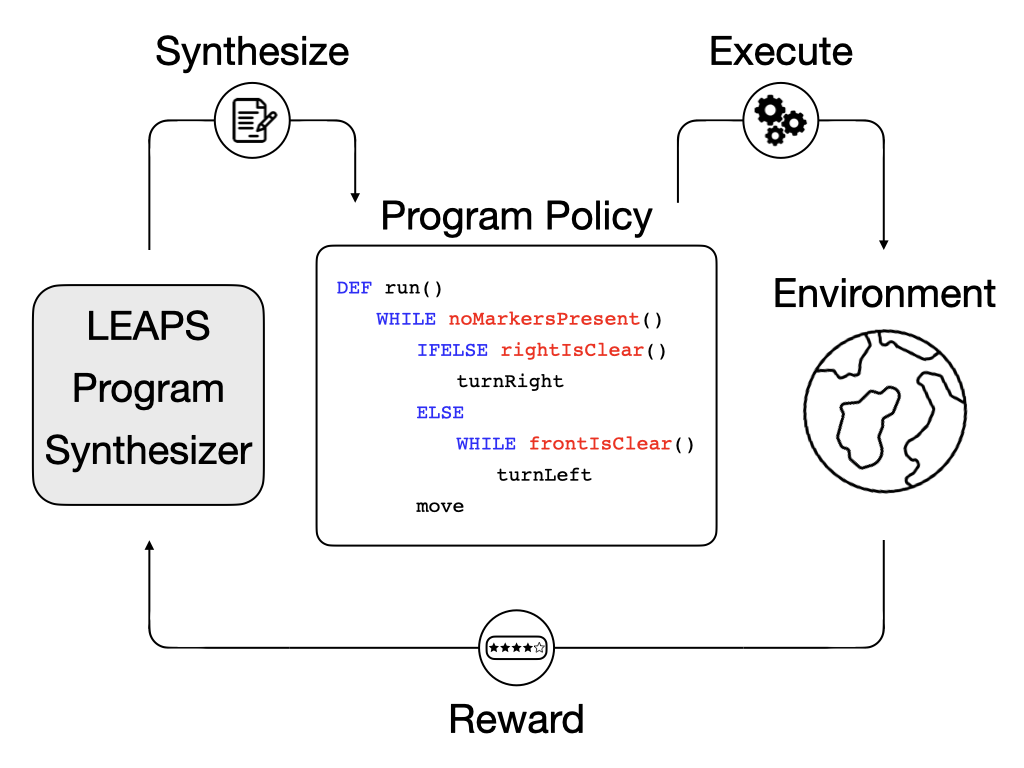
We present a framework that learns to synthesize a program, detailing the procedure to solve a task in a flexible and expressive manner, solely from reward signals. To alleviate the difficulty of learning to compose programs to induce the desired agent behavior from scratch, we propose to learn a program embedding space that continuously parameterizes diverse behaviors in an unsupervised manner and then search over the learned program embedding space to yield a program that maximizes the return for a given task.
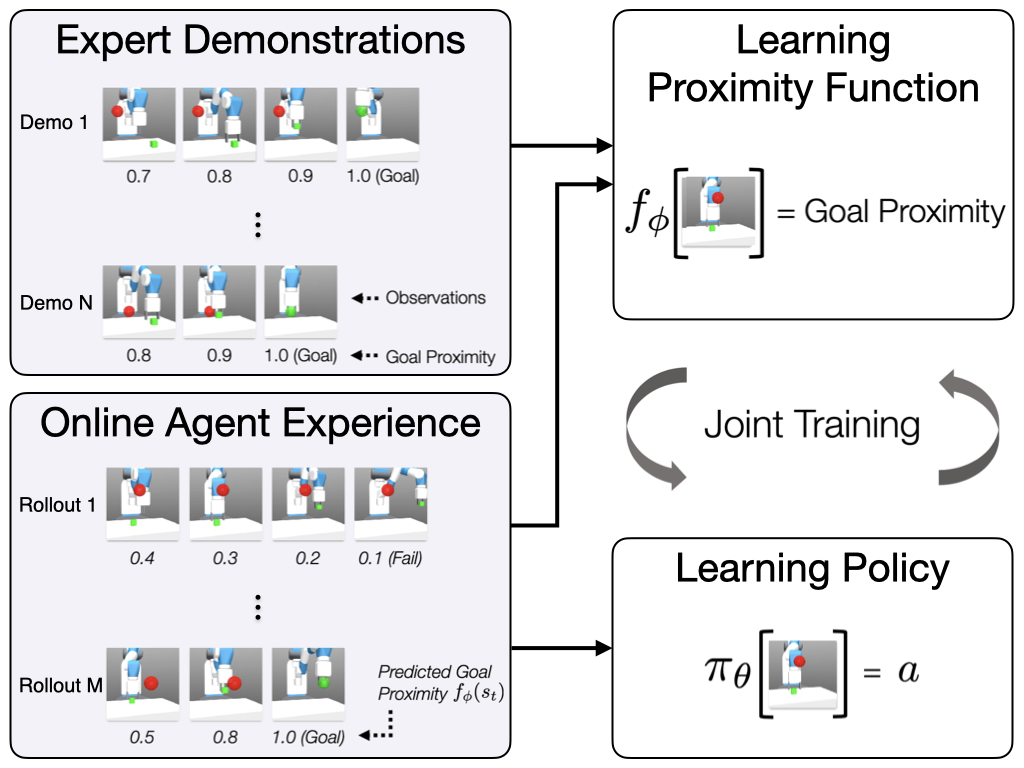
Task progress is intuitive and readily available task information that can guide an agent closer to the desired goal. Furthermore, a progress estimator can generalize to new situations. From this intuition, we propose a simple yet effective imitation learning from observation method for a goal-directed task using a learned goal proximity function as a task progress estimator, for better generalization to unseen states and goals. We obtain this goal proximity function from expert demonstrations and online agent experience, and then use the learned goal proximity as a dense reward for policy training.
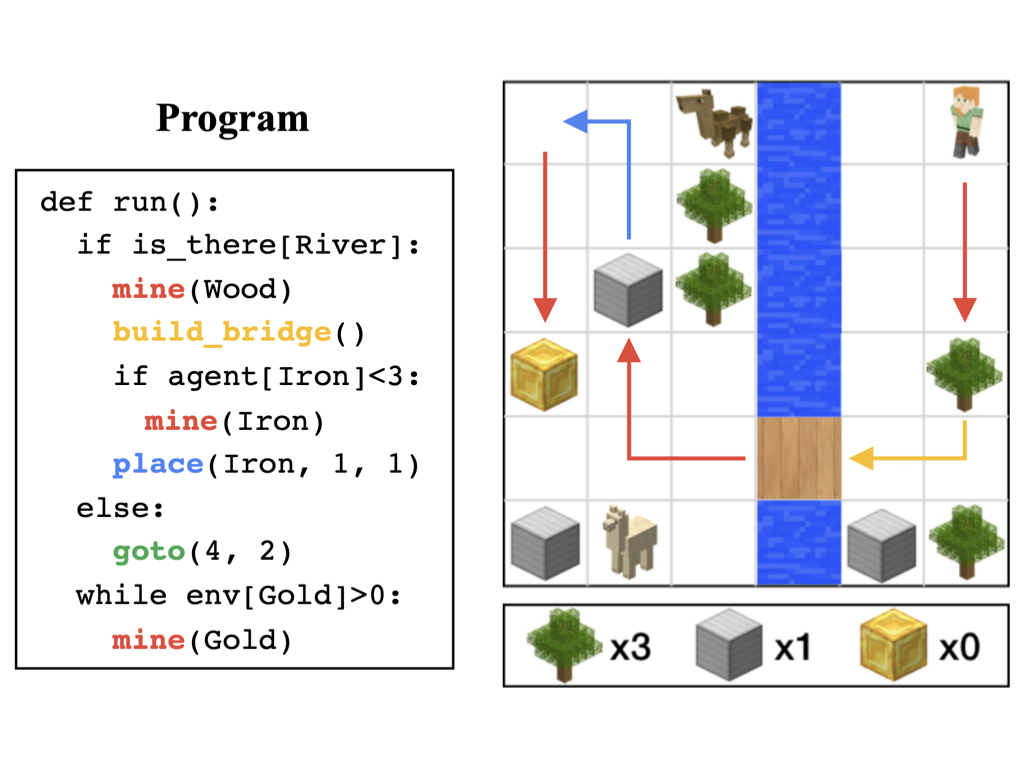
We propose to utilize programs, structured in a formal language, as a precise and expressive way to specify tasks, instead of natural languages which can often be ambiguous. We then devise a modular framework that learns to perform a task specified by a program – as different circumstances give rise to diverse ways to accomplish the task, our framework can perceive which circumstance it is currently under, and instruct a multitask policy accordingly to fulfill each subtask of the overall task.
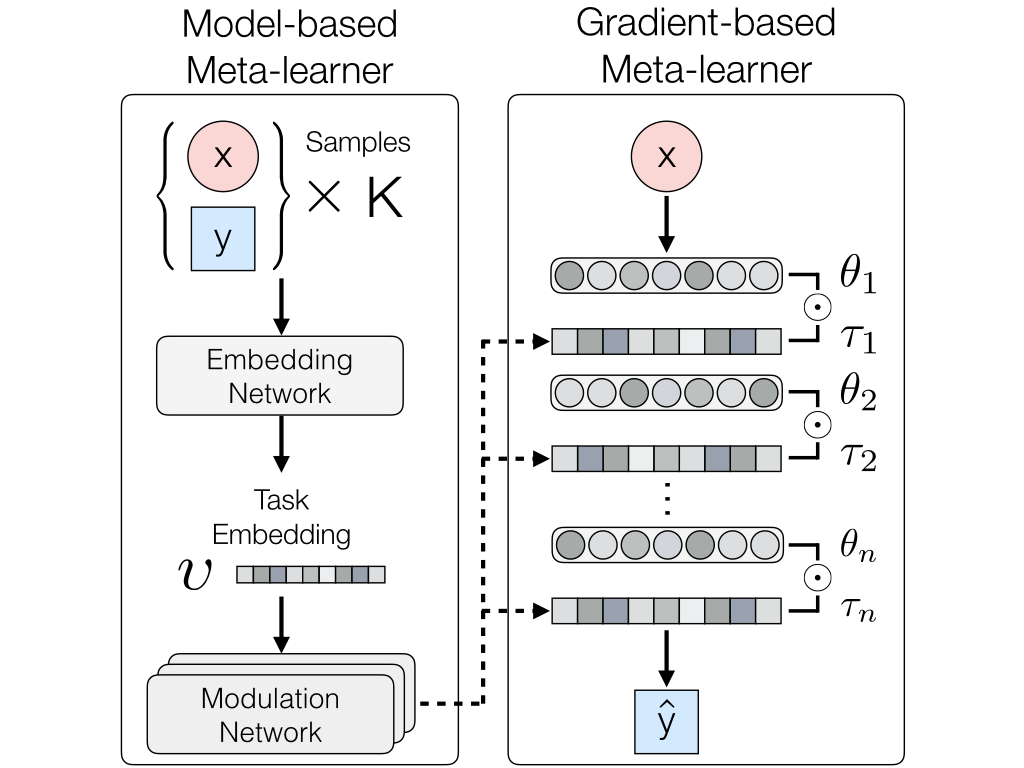
Model-agnostic meta-learners aim to acquire meta-prior parameters from a distribution of tasks and adapt to novel tasks with few gradient updates. Yet, seeking a common initialization shared across the entire task distribution substantially limits the diversity of the task distributions that they are able to learn from. We propose a multimodal MAML (MMAML) framework, which is able to modulate its meta-learned prior according to the identified mode, allowing more efficient fast adaptation.

We propose feedback adversarial learning (FAL) framework that can improve existing generative adversarial networks by leveraging spatial feedback from the discriminator. We formulate the generation task as a recurrent framework, in which the generator conditions on the discriminator spatial output response and its previous generation to improve generation quality over time - allowing the generator to attend and fix its previous mistakes.
Humans acquire complex skills by exploiting previously learned skills and making transitions between them. To empower machines with this ability, we propose a method that can learn transition policies which effectively connect primitive skills to perform sequential tasks without handcrafted rewards. To efficiently train our transition policies, we introduce proximity predictors which induce rewards gauging proximity to suitable initial states for the next skill.
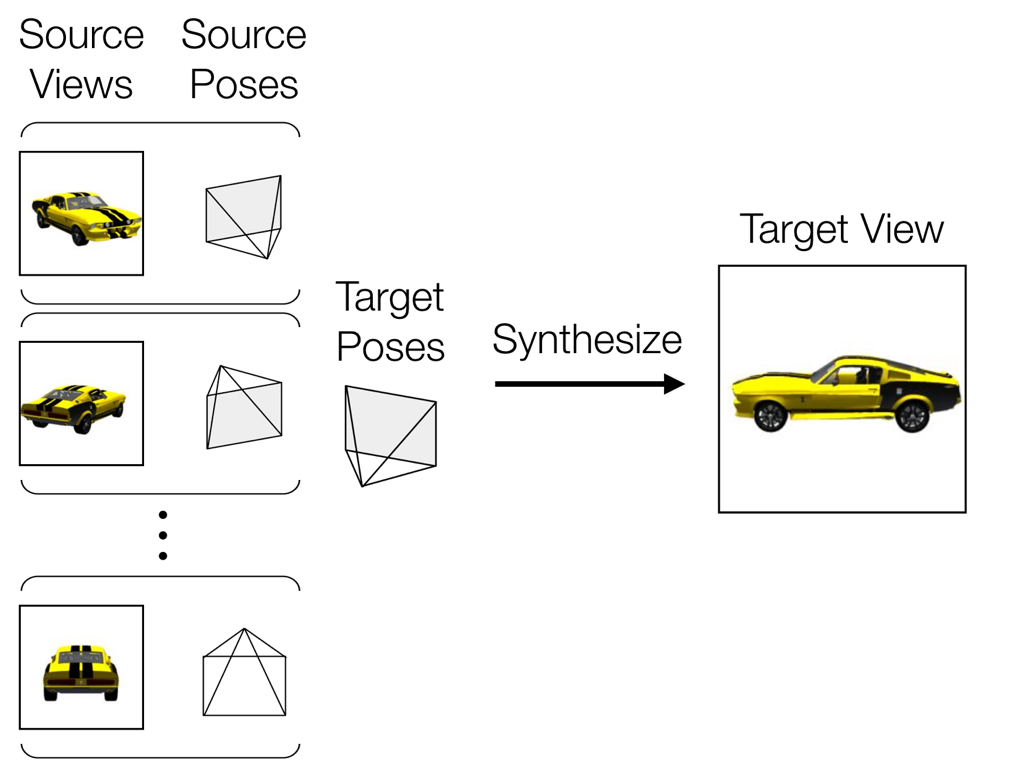
We aim to synthesize a target image with an arbitrary camera pose from multipple given source images. We propose an end-to-end trainable framework which consists of a flow prediction module and a pixel generation module to directly leverage information presented in source views as well as hallucinate missing pixels from statistical priors. We introduce a self-learned confidence aggregation mechanism to merge the predictions produced by the two modules given multi-view source images.
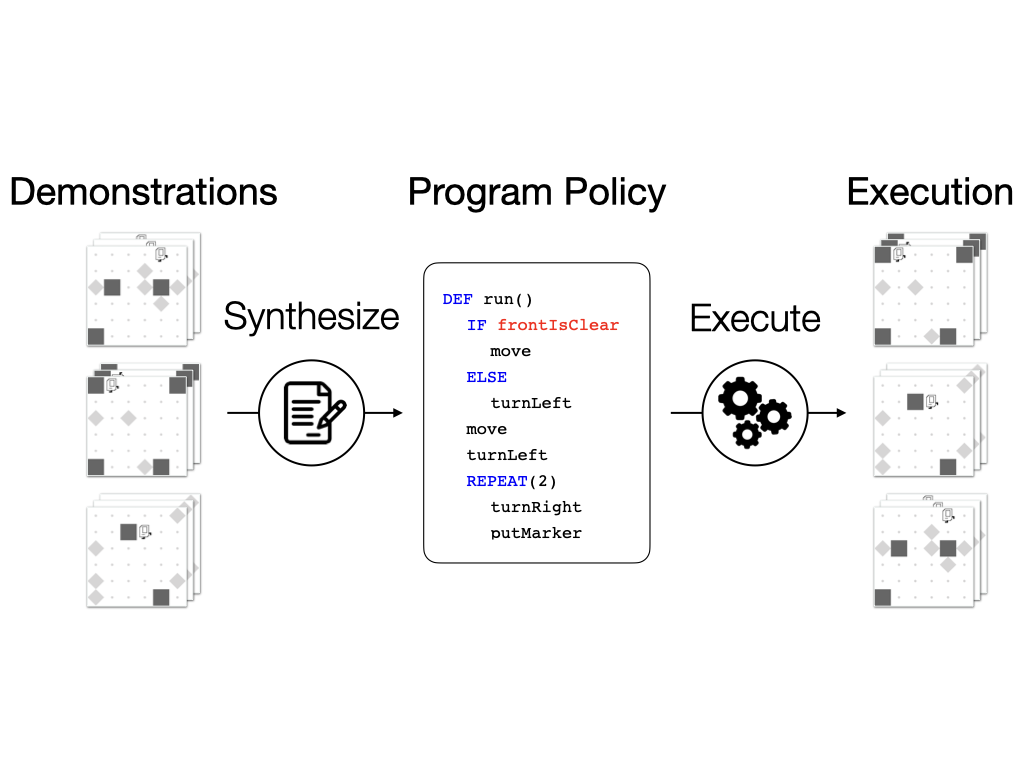
Interpreting decision making logic in demonstration videos is key to collaborating with and mimicking humans. To empower machines with this ability, we propose a framework that is able to explicitly synthesize underlying programs from behaviorally diverse and visually complicated demonstration videos. We introduce a summarizer module to improve the network’s ability to integrate multiple demonstrations and employ a multi-task objective to encourage the model to learn meaningful intermediate representations.